LLMs


Final tool functionalities
Summary
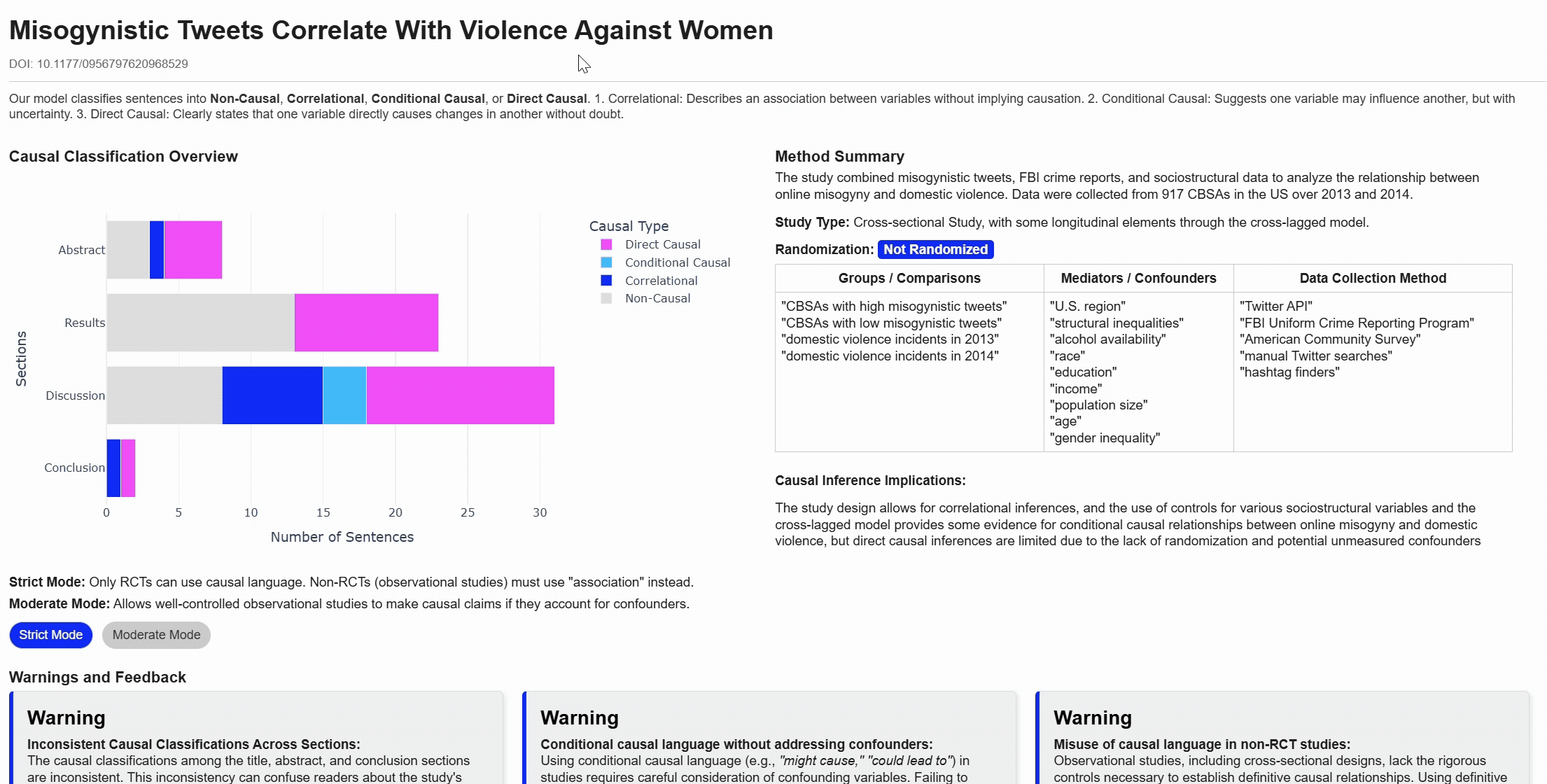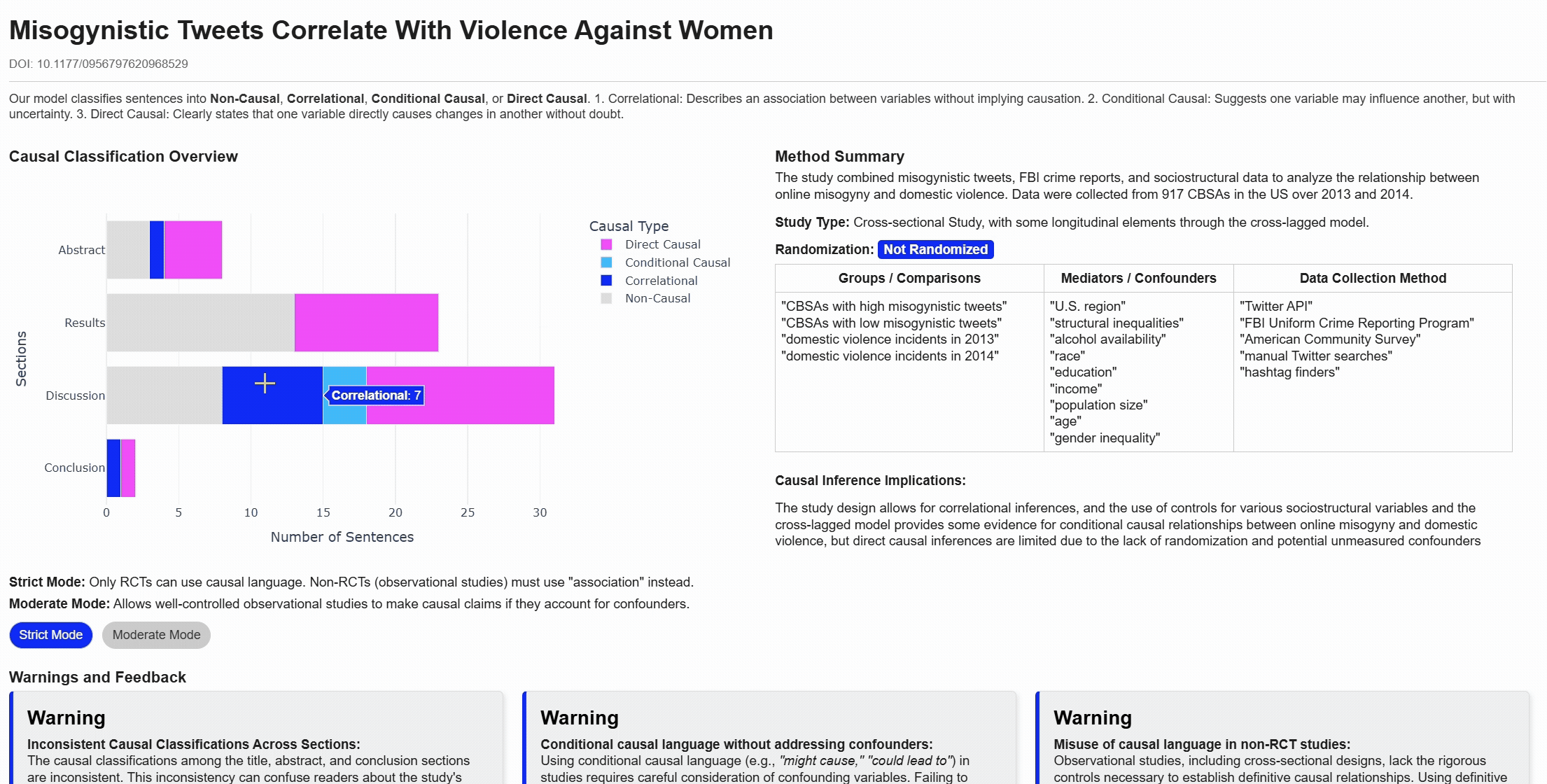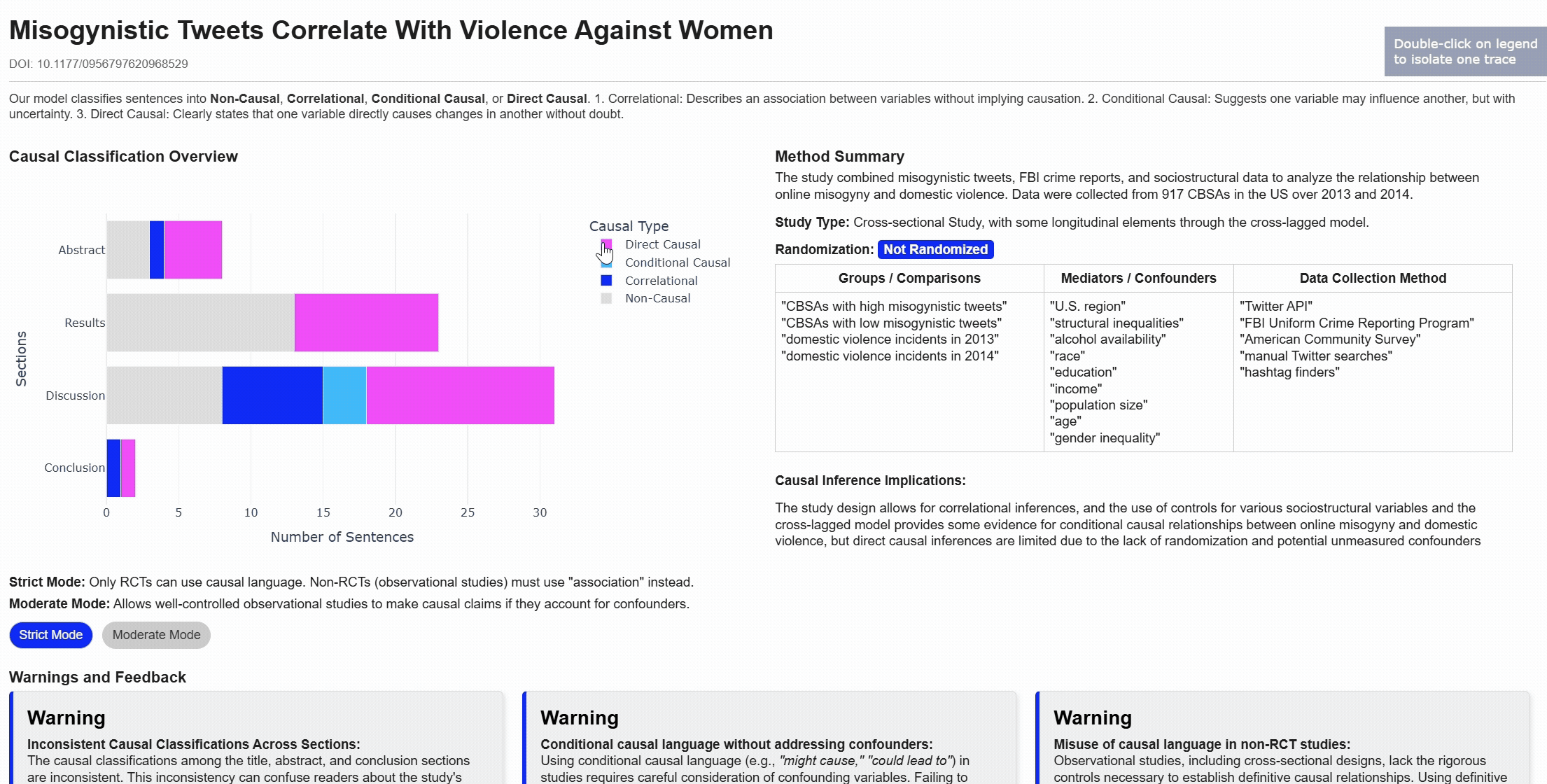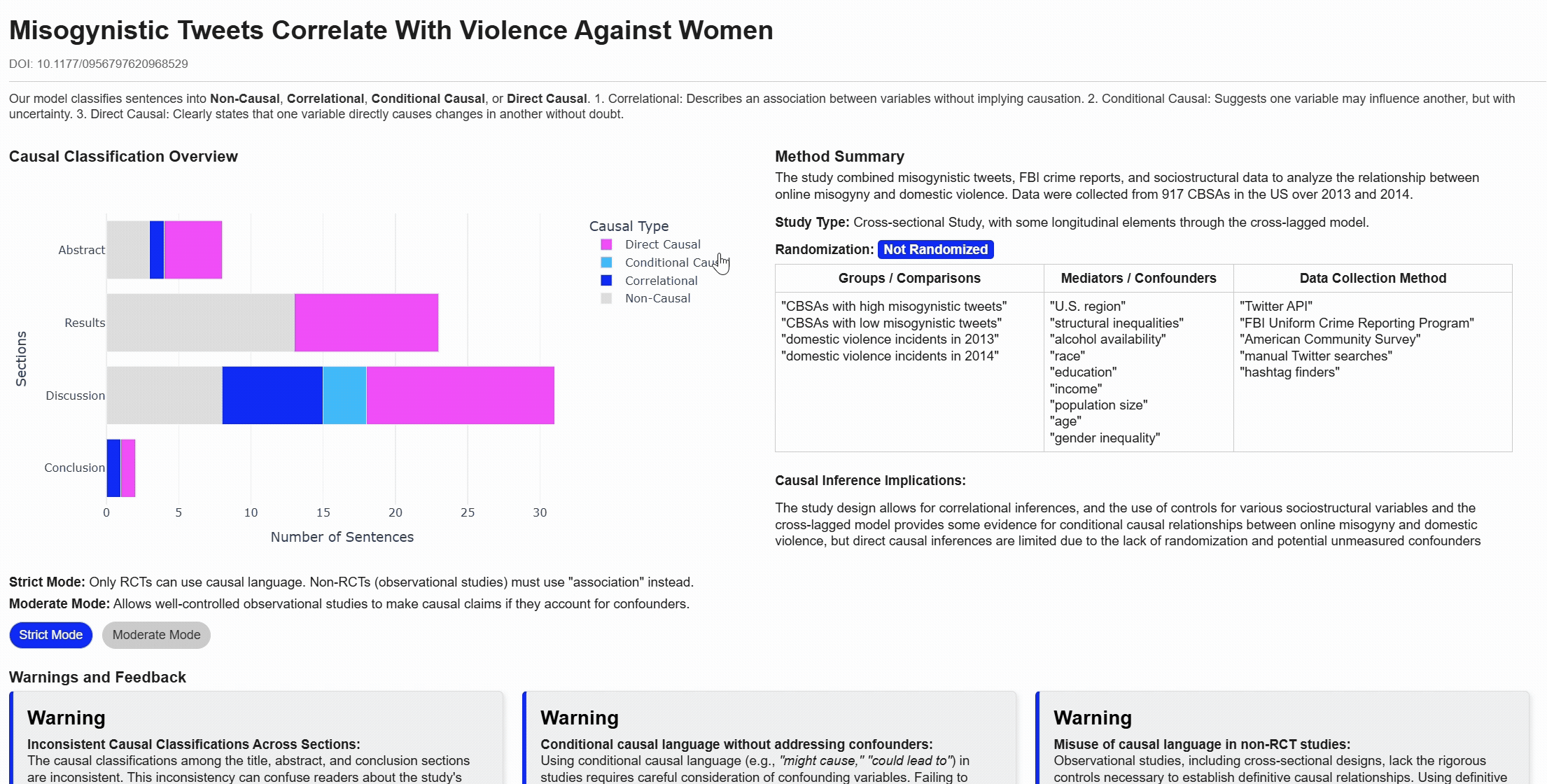
Align claims

Lenient vs Strict classifications

Explanations

Warnings

Try the demo version here
Context


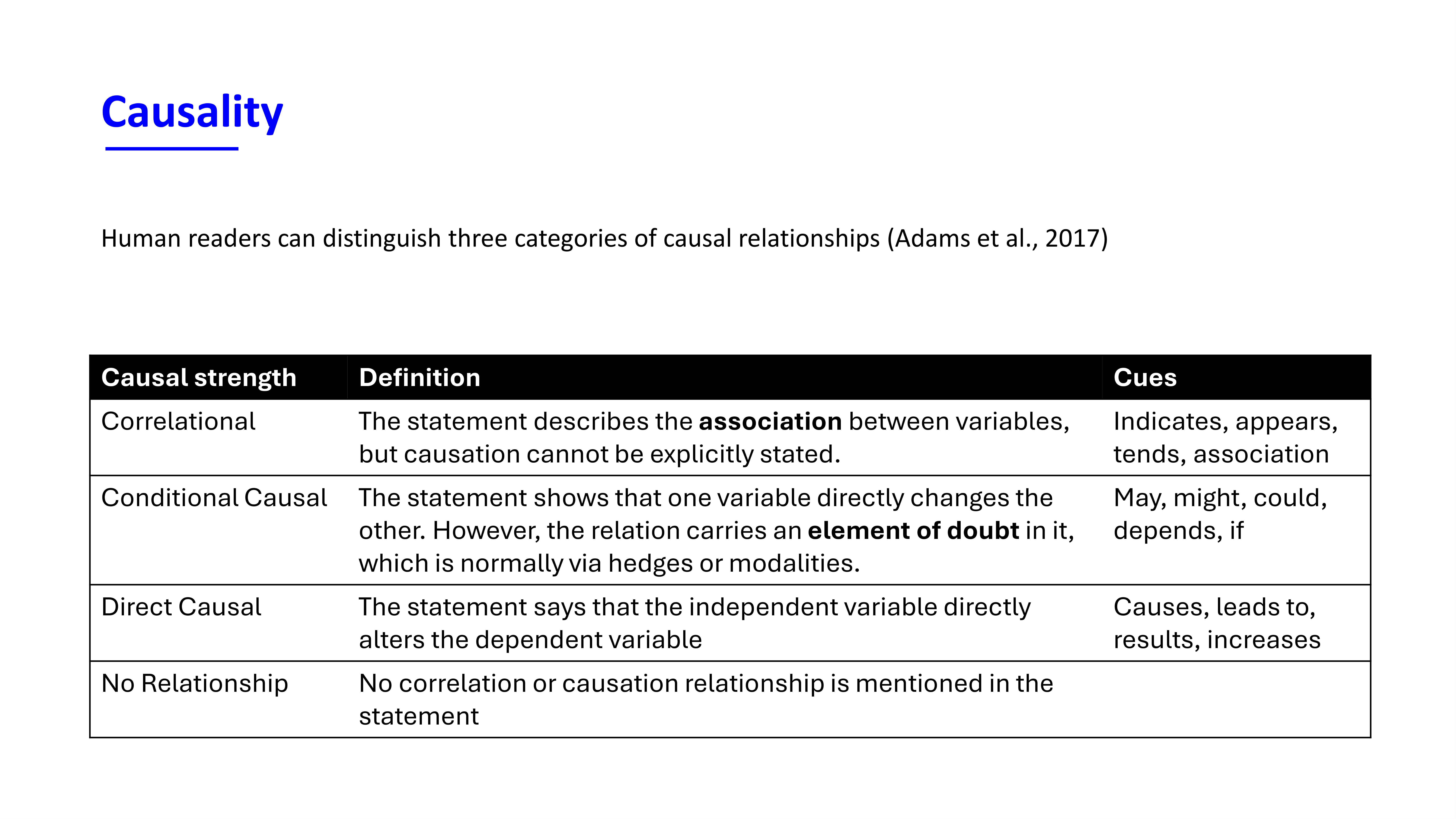
Three levels of causality
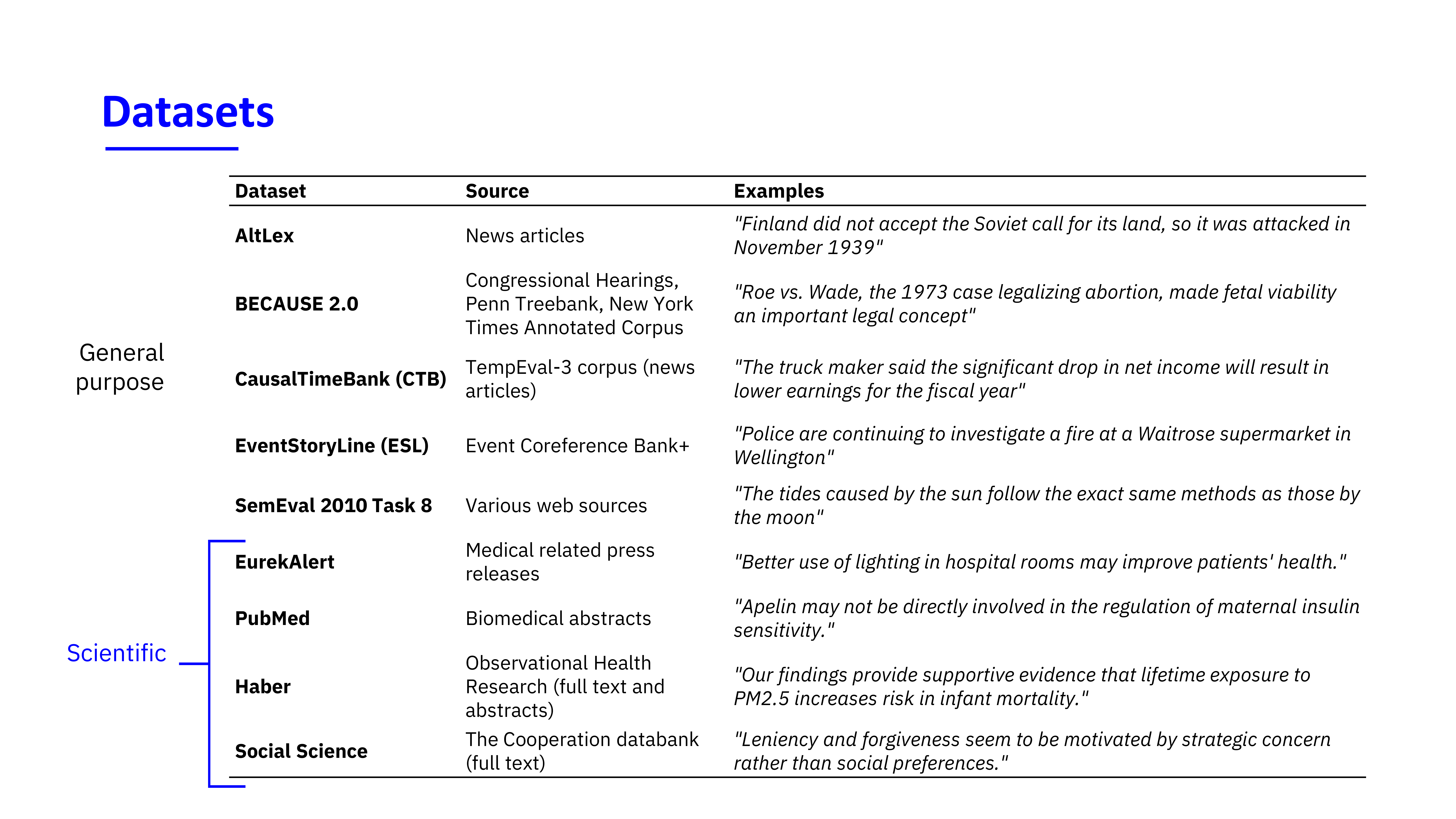
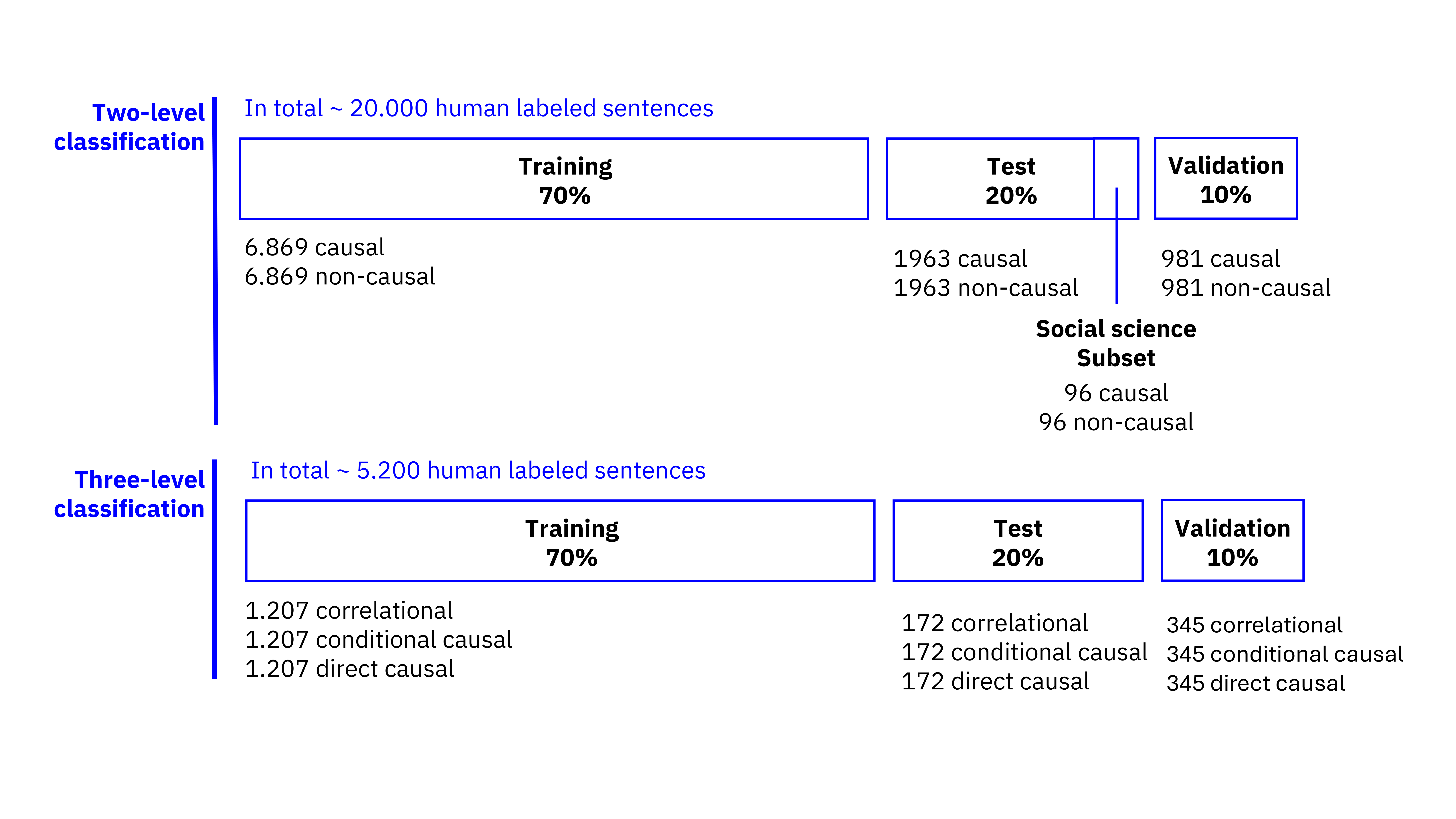
Training data
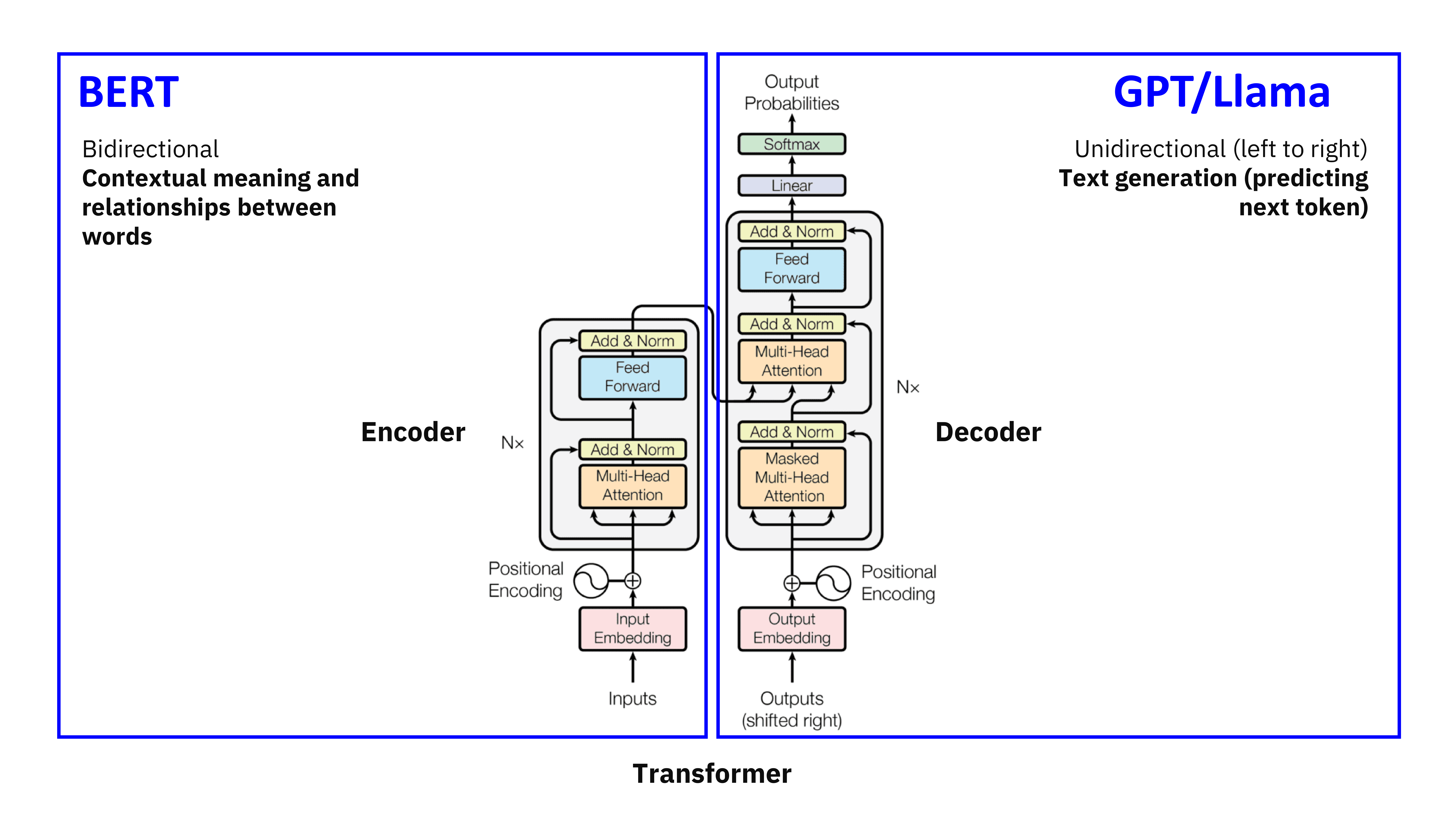
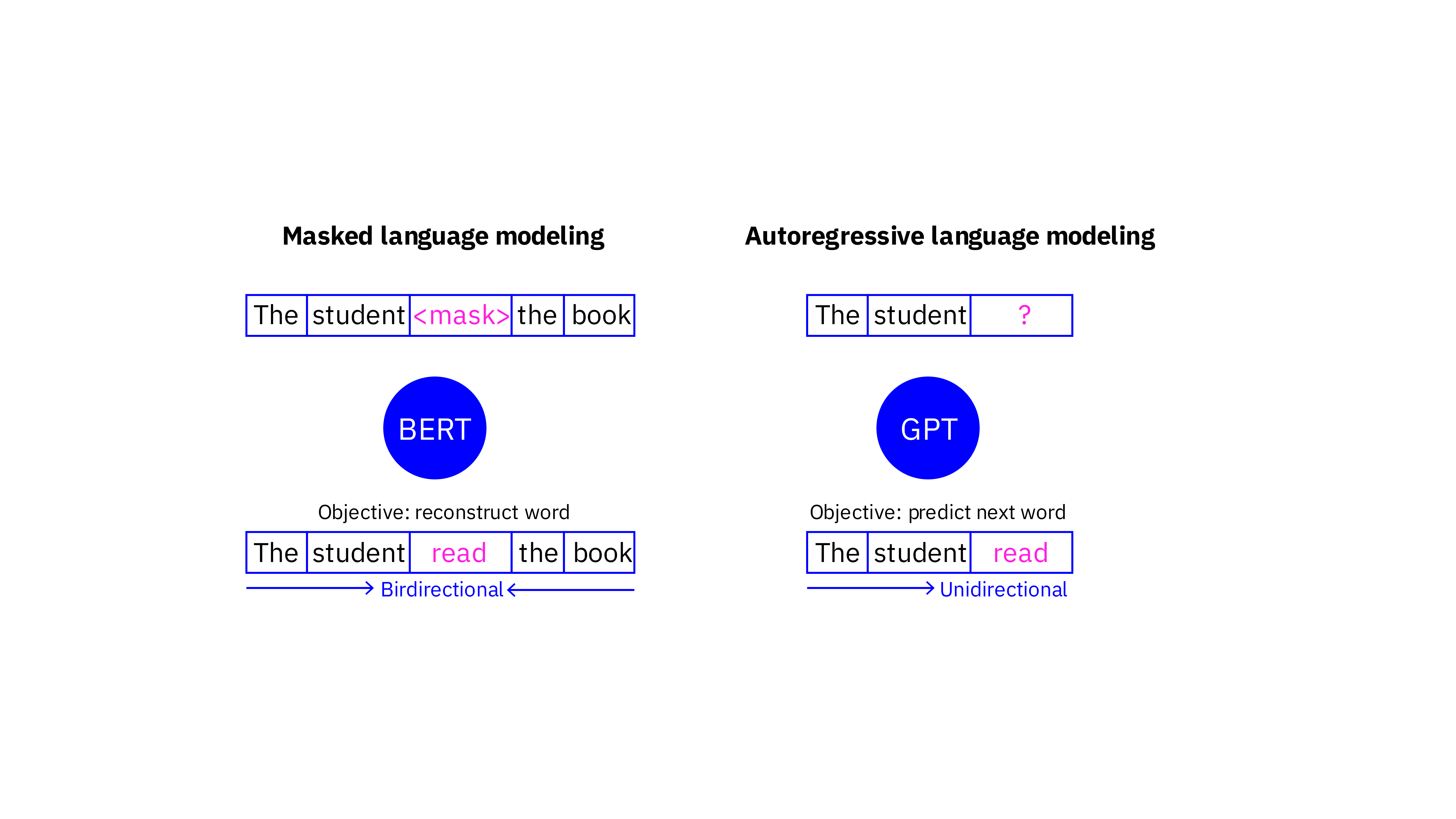
Model selection, is bigger always better?
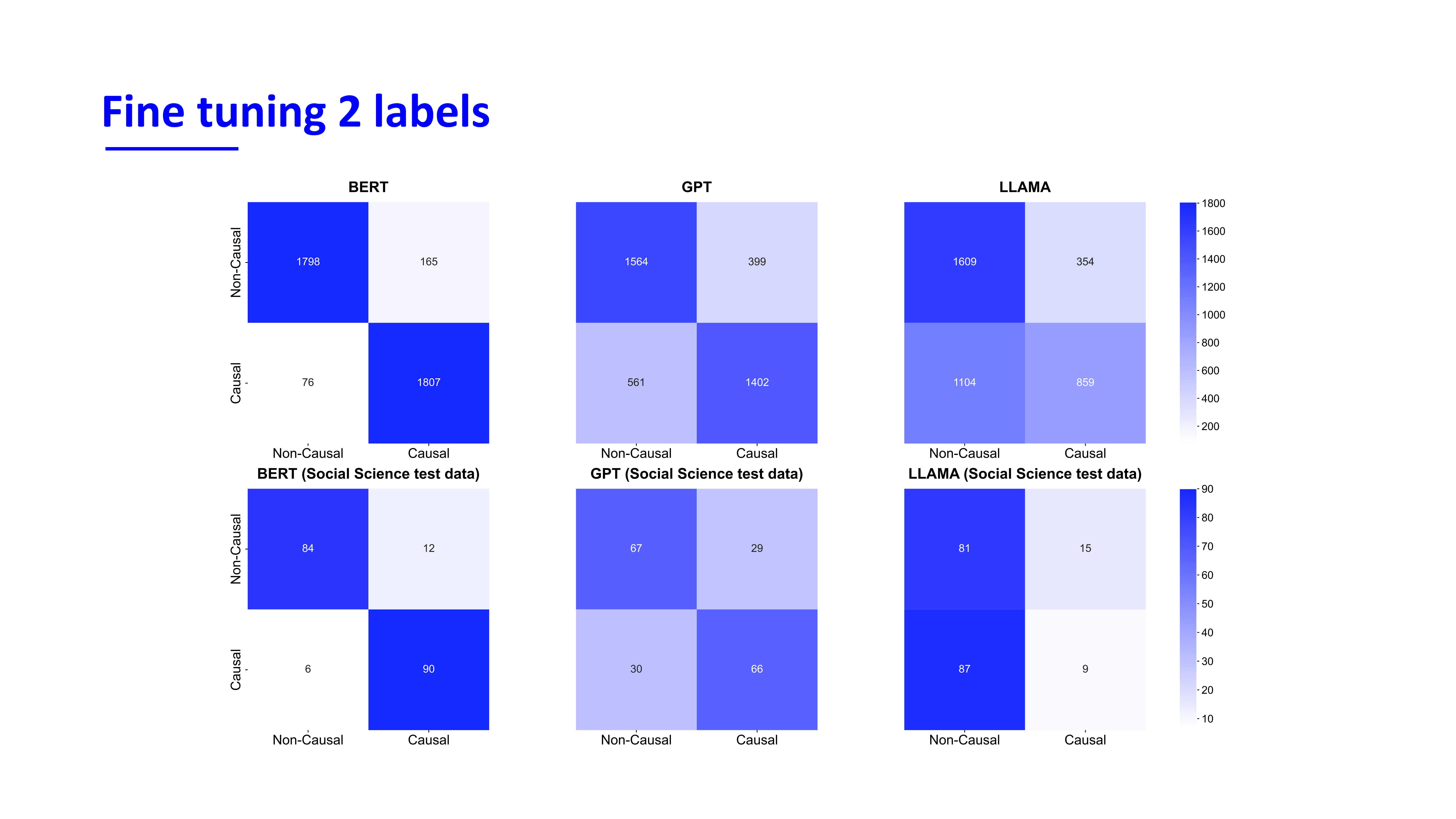
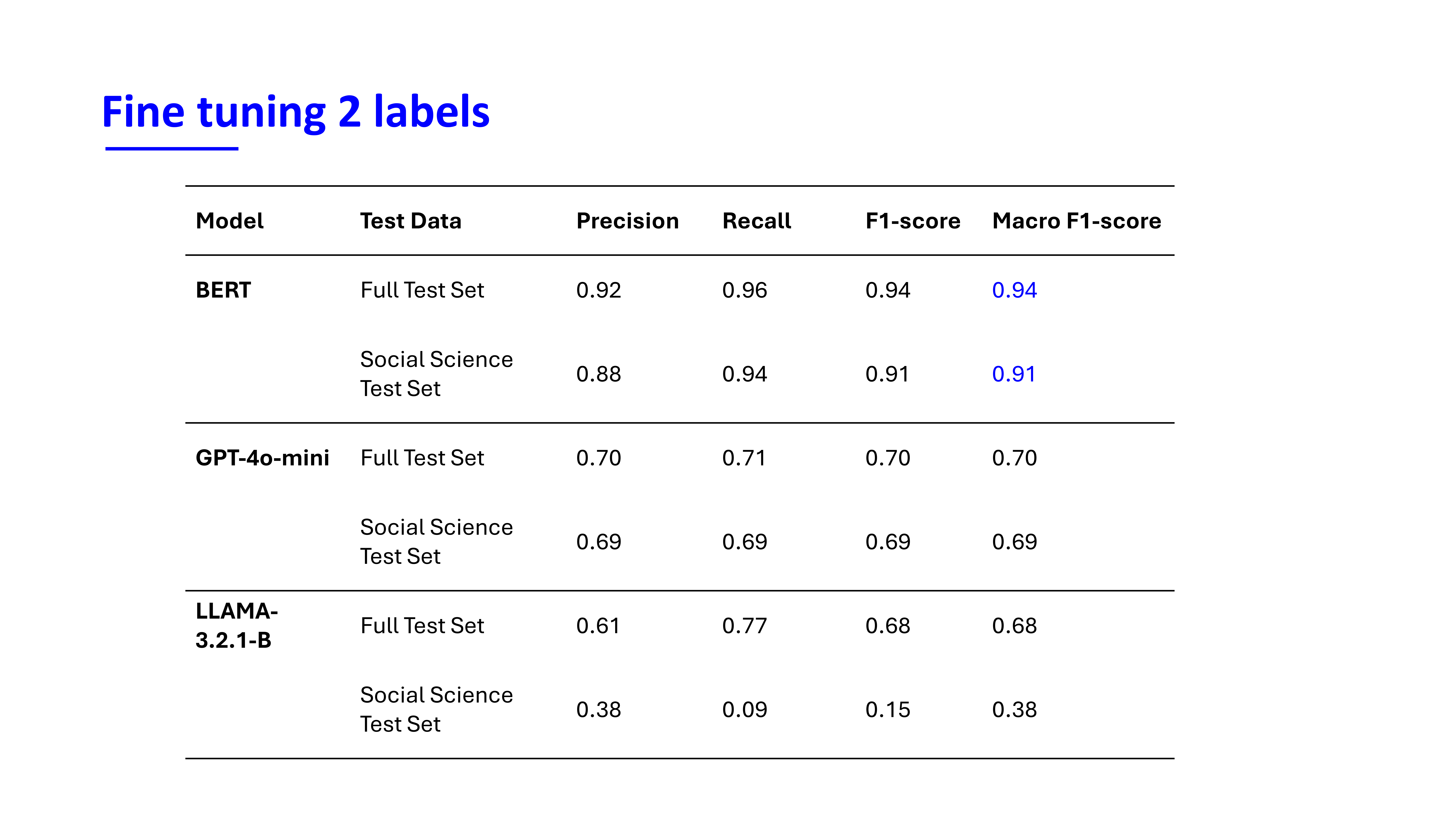
Evaluation 2 labels
Evaluation 3 labels
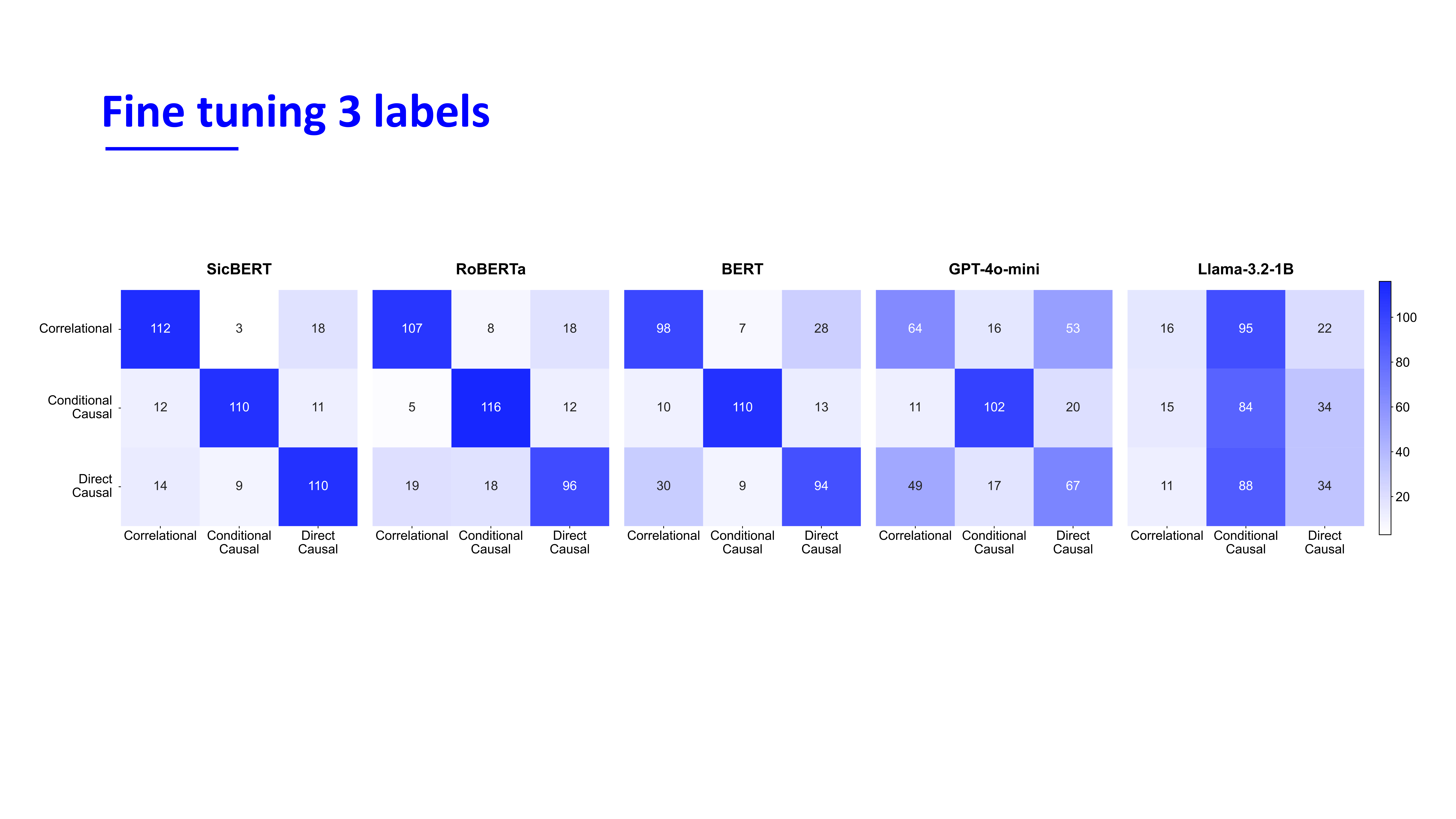
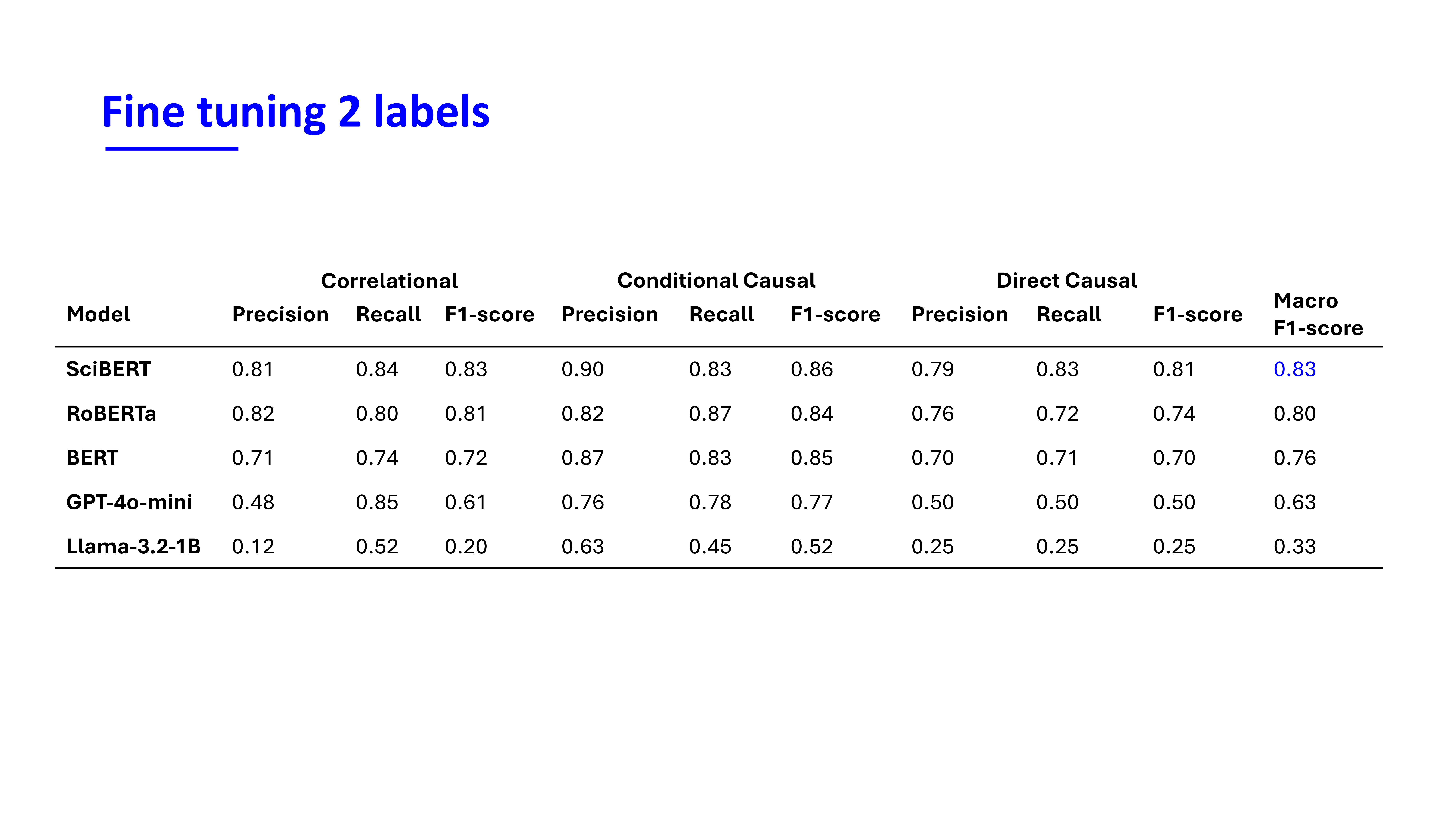
Evaluation final models
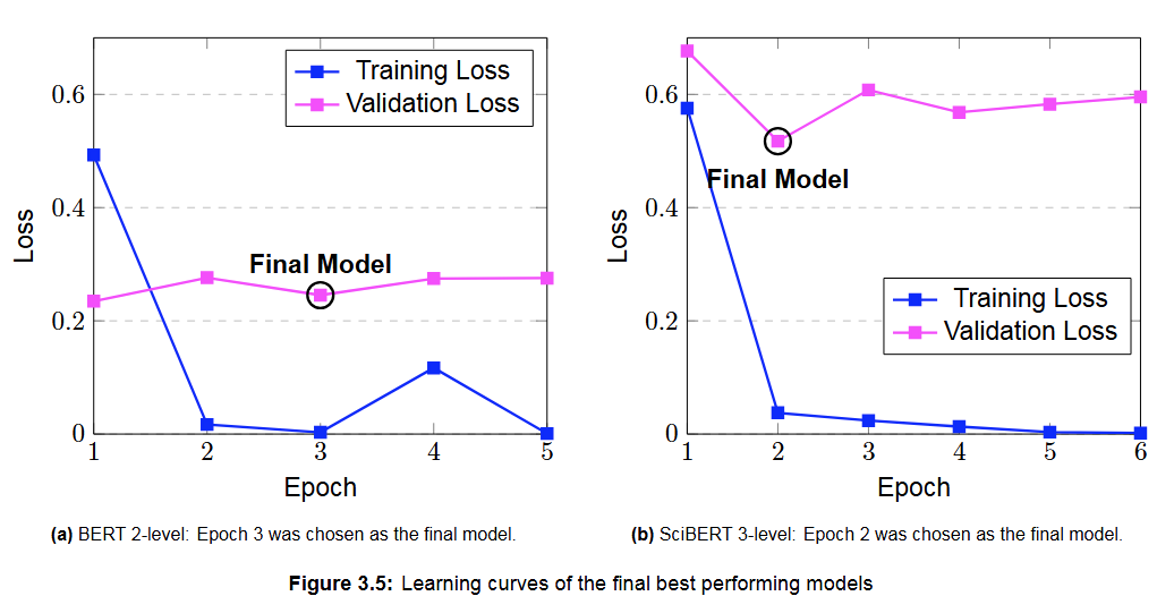

Integration into a Tool

The tool has been tested by 5 researchers on reviewing their own papers for causal language usage